调整 PostgreSQL 设置以提高性能
PostgreSQL 有许多配置选项可以调整以提高性能。以下是一些调整 PostgreSQL 性能的技巧。

max_connections
使用合理数量的连接,以便您可以为每个连接提供更多 RAM、磁盘时间和 CPU。为了避免出现 FATAL too many connections 错误,请在 PostgreSQL 前面使用连接池,例如,PgBouncer 是一个不错的选择。
max_connections = <4-8 * number_of_cpus>
在 SSD 上,将 max_connections 设置为磁盘可以处理的并发 I/O 请求数量 * CPU 数量。
shared_buffers
shared_buffers 控制 PostgreSQL 为将数据写入磁盘而保留多少内存。PostgreSQL 在共享缓冲区中选择一个空闲的 RAM 页面,将数据写入其中,将该页面标记为脏页面,并让另一个进程异步地在后台将脏页面写入磁盘。
如果可以找到您正在读取的数据,PostgreSQL 也会使用共享缓冲区作为缓存。有关详细说明,请参阅 此。
警告
过低地降低共享缓冲区的值可能会影响写入性能。
shared_buffers = <20-40% of RAM>
work_mem
work_mem 指定每个 PostgreSQL 查询在回退到临时磁盘文件之前可以使用的最大内存量。每个查询都可能多次请求 work_mem 定义的值,因此请谨慎使用较大的值。
work_mem = <1-5% of RAM>
如果您的查询经常使用临时文件,请考虑增加 work_mem 值并通过 max_connections 降低并发查询的最大数量。
work_mem 的最佳值会因您的特定工作负载、硬件资源和可用内存而异。随着工作负载的不断发展,需要定期监控、基准测试和调整以确保最佳性能。
maintenance_work_mem
maintenance_work_mem 限制维护操作(例如 CREATE INDEX 或 ALTER TABLE)可以使用的最大内存量。
maintenance_work_mem = <10-20% of RAM>
effective_cache_size
effective_cache_size 向 PostgreSQL 提供有关它可以预期在系统缓存或 ZFS ARC 中找到多少数据的提示。
effective_cache_size = <70-80% of RAM>
自动真空
自动真空是一个后台进程,负责删除死元组(已删除的行)并更新 PostgreSQL 查询规划器用于优化查询的数据库统计信息。
默认的自动真空设置相当保守,可以增加这些设置以让自动真空更频繁地运行并使用更多资源
# Allow vacuum to do more work before sleeping.
# 500-1000 should be enough.
vacuum_cost_limit = 500
# Use smaller nap time if you have many tables.
autovacuum_naptime = 10s
# Ran autovacuum when 5% of rows are inserted/updated/deleted.
autovacuum_vacuum_scale_factor = 0.05
autovacuum_vacuum_insert_scale_factor = 0.05
您也可以运行更少的自动真空工作程序,但为每个工作程序提供更多内存
# Run 2 autovacuum workers instead of 3.
autovacuum_max_workers = 2
# But give them more memory.
autovacuum_work_mem = <2-3% of RAM>
WAL
PostgreSQL WAL 代表预写日志。预写日志是一个事务日志,它记录在将更改写入实际数据文件之前对数据库所做的更改。
当事务修改 PostgreSQL 中的数据时,更改首先写入 WAL,然后再应用于实际的数据库文件。此过程确保在将事务视为已提交之前,更改已持久记录在磁盘上。
以下 WAL 设置在大多数情况下都能很好地工作,唯一的缺点是数据库崩溃时的恢复时间会增加
wal_compression = on
min_wal_size = 1GB
max_wal_size = 8GB
wal_buffers = 16MB
checkpoint_timeout = 30min
checkpoint_completion_target = 0.9
SSD
如果您使用的是固态硬盘,请考虑调整以下设置
# Cost of a randomaly fetched disk page.
# SSDs have low random reads cost relative to sequential reads.
random_page_cost = 1.1
# Number of simultaneous requests that can be handled efficiently by the disk subsystem.
# SSDs can handle more concurrent requests.
effective_io_concurrency = 200
超时
您可以使用以下设置告诉 PostgreSQL 取消缓慢的查询
# Cancel queries slower than 5 seconds.
statement_timeout = 5000
# Max time to wait for a lock.
lock_timeout = 5000
日志记录
良好的日志记录可以告诉您查询何时过慢或是否存在任何其他问题
# Log queries slower than 500ms.
log_min_duration_statement = 500
# Log queries that use temp files.
log_temp_files = 0
# Log queries that wait for locks.
log_lock_waits = on
巨型页面
巨型页面,也称为大页面,是操作系统中的一种内存管理功能,允许应用程序分配和使用比标准小页面更大的页面大小。在 PostgreSQL 等数据库的上下文中,巨型页面可以通过减少内存开销和提高内存访问效率来提供性能优势。
如果您的服务器拥有 128 GB 或更多 RAM,请考虑使用巨型页面来减少内存页面的数量,并最大限度地减少由管理大量页面引入的 开销。
使用索引
索引可以通过允许 PostgreSQL 快速定位所需数据来显著提高查询性能。确保您的表具有根据正在运行的查询而创建的适当索引。
使用 EXPLAIN 命令分析查询并确定优化区域。
EXPLAIN ANALYZE SELECT ...;
分区
如果您的表非常大,请考虑对其进行分区。分区可以通过允许 PostgreSQL 快速访问相关数据来提高查询性能。
请参阅 PostgreSQL 表分区。
游标分页
在处理大型数据集时,例如在需要显示大量记录的 Web 应用程序中。请考虑使用 游标分页。
监控性能
定期监控数据库活动可以帮助识别性能问题。使用 pg_stat_activity、pg_stat_database 和 pg_stat_user_tables 等表来监控数据库活动并确定优化区域。
要 监控 PostgreSQL,您可以使用 OpenTelemetry PostgreSQL 接收器,它随 OpenTelemetry 收集器一起提供。
Uptrace 是一个 OpenTelemetry APM,它支持分布式跟踪、指标和日志。您可以使用它来监控应用程序并排查问题。
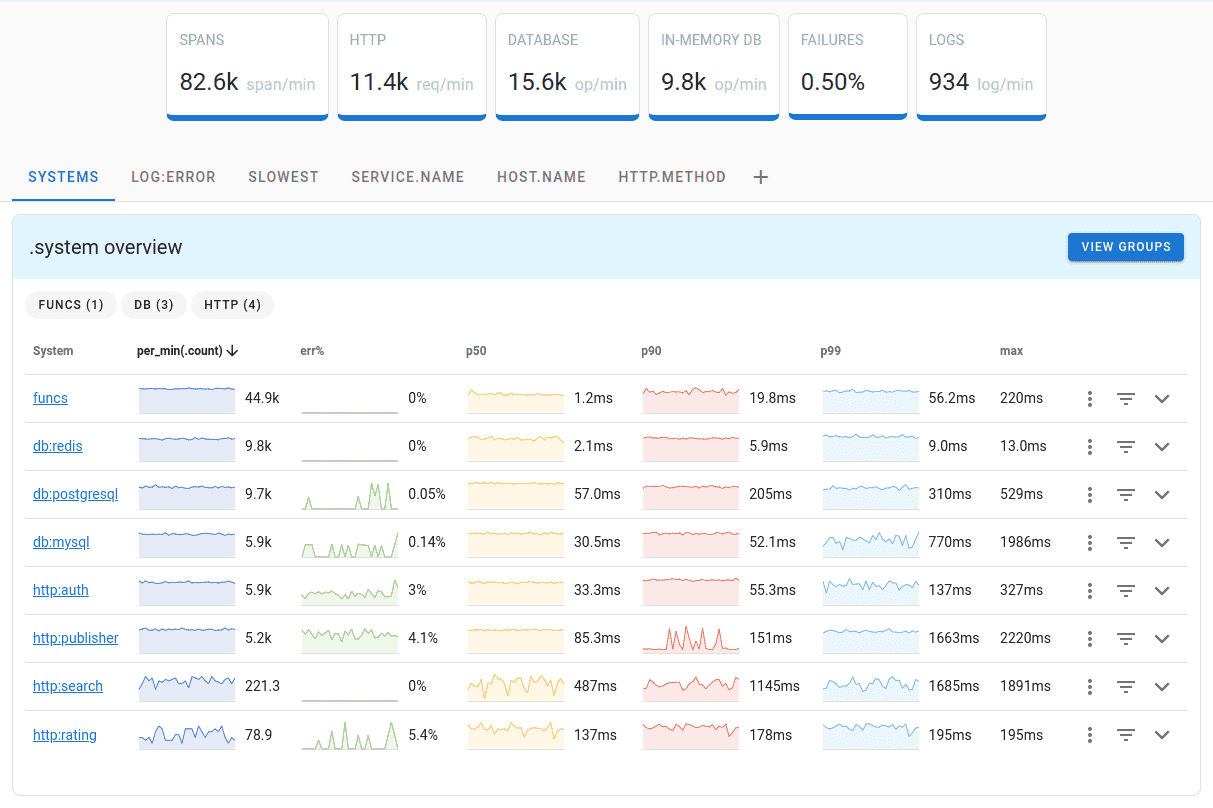
Uptrace 带有一个直观的查询构建器、丰富的仪表板、带有通知的警报规则以及大多数语言和框架的集成。
Uptrace 可以在一台服务器上处理数十亿个跨度和指标,并允许您以低 10 倍的成本监控您的应用程序。